Forse gli unici conoscitori della statistica migliori degli statistici sono i fisici. Dico questo perché molti dei progressi maggiori, specialmente in materia di statistica bayesiana, hanno trovato origine in soluzioni a problemi posti dai fisici.
Il caso più eclatante è forse la distribuzione dell’energia di Boltzmann. Questa distribuzione rappresenta il fondamento del potente algoritmo di ottimizzazione del Simulated Annealing (SANN) proposto negli anni 80 da Hinton e Hopfield, che di fatto rappresenta un’applicazione dell’algoritmo Metropolis-Hastings sulla distribuzione di Boltzmann.
Attenzione: io la chiamo Distribuzione di Boltzmann, ma la sua definizione è praticamente equivalente a quella della cosidetta Misura di Gibbs o Distribuzione di Gibbs. Non va invce confusa con la distribuzione di Maxwell-Boltzmann, alla quale è ispirata, ma che invece tratta direttamente la distribuzione congiunta di velocità e massa delle particelle di gas.
Che cosa rappresenta questa distribuzione? Prima di definire la distribuzione di Boltzmann, è bene definire l’oggetto di questa distribuzione: l’energia.
L’energia può essere vista come una misura di instabilità, o di disordine (come l’entropia) o di perdita (come l’errore). La distribuzione di Boltzmann consente di passare da una qualsiasi funzione di energia definita positiva a una funzione di verosimiglianza (strumento molto potente che da accesso a molti strumenti statistici, tra cui i metodi Markov-Chain Monte Carlo come Metropolis-Hastings).
La distribuzione di Boltzmann è definita su una funzione di energia con supporto positivo.
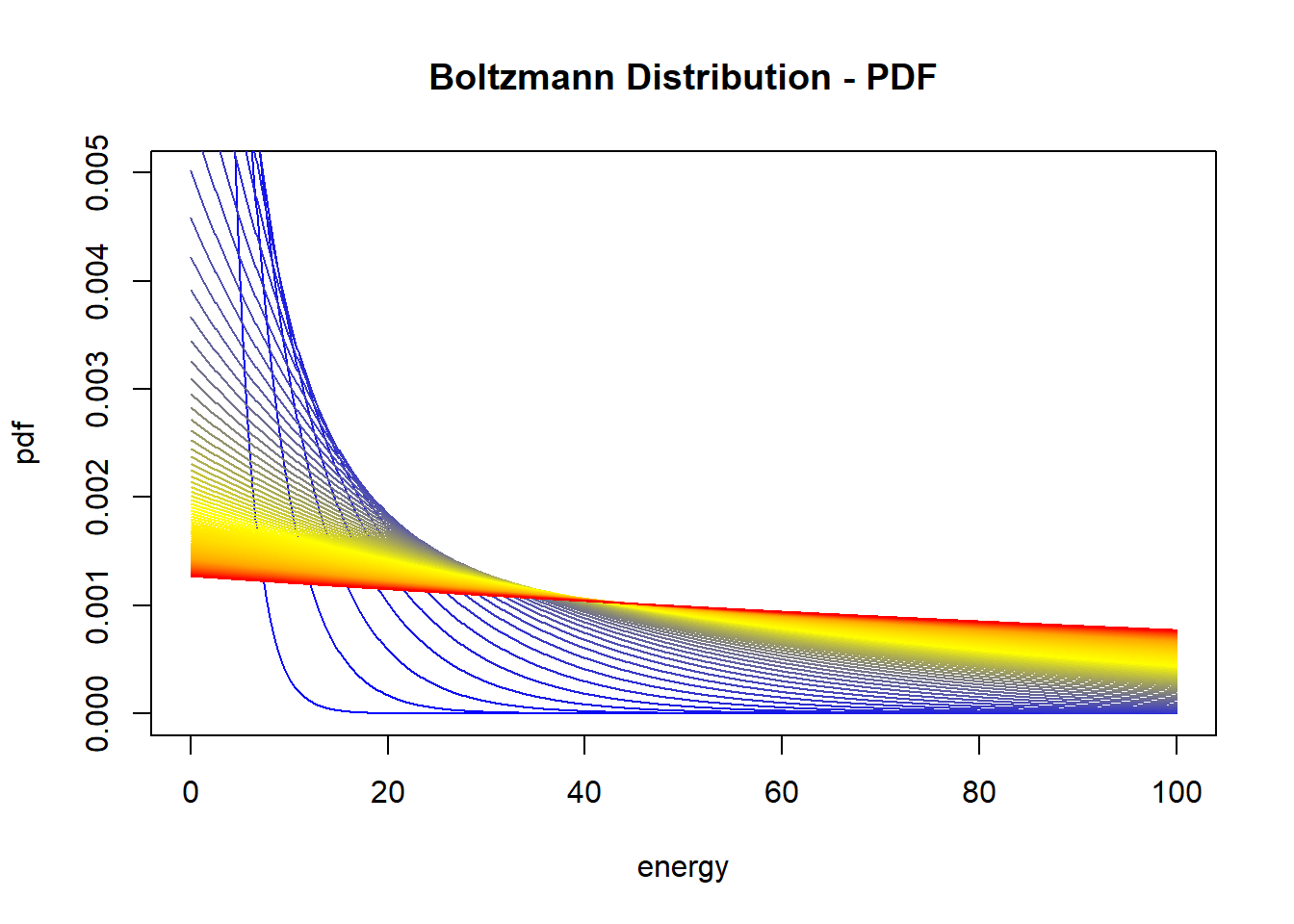
Ma considera anche un secondo parametro: la temperatura. Mentre l’energia può essere vista come l’instabilità di un sistema, la temperatura rappresenta la tensione tra il sistema e l’ambiente circostante. Pensiamo a una batteria messa dentro un forno. La batteria potrebbe essere instabile a causa del suo stato di decomposizione interno, ma la temperatura causata dal forno potrebbe aggiungere un livello di instabilità ulteriore. Maggiore è l’instabilità, minore è la verosimiglianza sotto la distribuzione di Boltzmann.
In generale, è utile considerare questi 4 concetti:
il sistema: è una struttura o un architettura complessa, rappresentante un oggetto, che può essere inserito in un qualche ambiente o contesto
lo stato (del sistema): è una configurazione in cui il sistema può trovarsi. Rappresenta la composizione interna del sistema
la temperatura: dice quanto il sistema si trova sotto pressione a causa dell’ambiente circostante, e non dipende dallo stato del sistema.
l’energia: dice quanto il sistema si trova sotto pressione quando si trova in uno stato in particolare. è diretta funzione dello stato del sistema.
Il quinto e ultimo concetto è la verosimiglianza sotto la distribuzione di Boltzmann: è una funzione che dipende dall’energia (e attraverso di essa dallo stato) e dalla temperatura (e attraverso di essa dell’ambiente) del sistema. La verosimiglianza di Bolztmann approssima l’uniforme per un livello di temperatura che tende a infinito.
con \(Z\) funzione di partizione o costante di normalizzazione
\[Z = \sum_x \exp\left(-\frac{E(x)}{T}\right)\]
I valori si interpretano come segue:
\(X\) rappresenta una variabile aleatoria o un processo stocastico (un insieme di variabili aleatorie) e \(x\) rappresenta il valore o i valori che assume \(X\) in corrispondenza di uno stato in cui si trova il sistema (\(x\) è lo stato, \(X\) è il sistema)
\(T\) è uno scalare positivo, che rappresenta la temperatura del sistema. Si vede che se \(T\) diventa alto il numeratore della pdf diventa \(\exp(0)=1\) per cui la distribuzione di Bolztmann diventa effettivamente una uniforme (gli stati hanno tutti la stessa probabilità di verificarsi)
\(E\) è una funzione che prende come input definito sullo spazio degli stati \(x\) e restituisce un output scalare definito sui reali positivi. è la funzione di energia, ed è il cuore della distribuzione di Boltzmann.
\(Z\) è una sommatoria del numeratore della pdf sullo spazio degli stati, necessaria per integrare a 1 e rendere la funzione una densità di probabilità.
Di seguito la pdf della distribuzione. Colori caldi rappresentano una più alta temperatura.
La distribuzione di Boltzmann è stata fondamentale per la definizione di molti modelli probabilistici, in particolare per tutti i processi stocastici basati sulle Reti di Markov. Si tratta di grafi indiretti e ciclici di variabili aleatorie, che rappresentano un’alternativa potente al framework delle Reti Bayesiane.